Python爬取音视频节目
今天做了爬取音视频节目的实验,主要针对两类:一是固有链接的音视频节目,二是非固有链接的音视频节目,现总结相关内容如下:
固有链接的音视频节目
这类网站一般搭建的比较简单,直接获取音视频节目的链接进行保存即可。
例子:https://www.thepaper.cn/list_26913 https://haokan.baidu.com/
非固有链接的音视频节目(以 B 站为例)
这类音视频节目的获取需要考虑三点:
- CDN:一个音视频节目是否从多个 CDN 上进行获取;
- 反爬策略:构造requests请求的时候需要考虑头部信息,比如 Referer和UserAgent
- 音视频整合:B 站爬取得到的是音频和视频内容,分别获取之后需要使用工具进行整合
系统结构
使用到的工具
- IntelliJ IDEA 2019.1.4
- Python3.8(编程语言)
- requests库(发送http请求)
- lxml库(xpath解析)
- json库(解析json数据)
- ffmpeg(合并音频和视频)
功能实现原理
- 输入 BV 开头音视频节目编号拼接成为有效的包含音视频节目的 url
- 构造 request 请求访问视频页面,得到页面的响应信息
- 使用 lxml 库与 json 库从返回的响应信息中提取到视频资源的链接
- 模拟浏览器请求获取音频和视频资源
- 将获得的音频和视频资源合并保存到本地(ffmpeg)
实现代码
了解url结构
到 Bilibili 首页随便点开一个音视频节目,观察节目的 URL,可以看到该 url 包含一个正常的文件路径和一个参数 p 。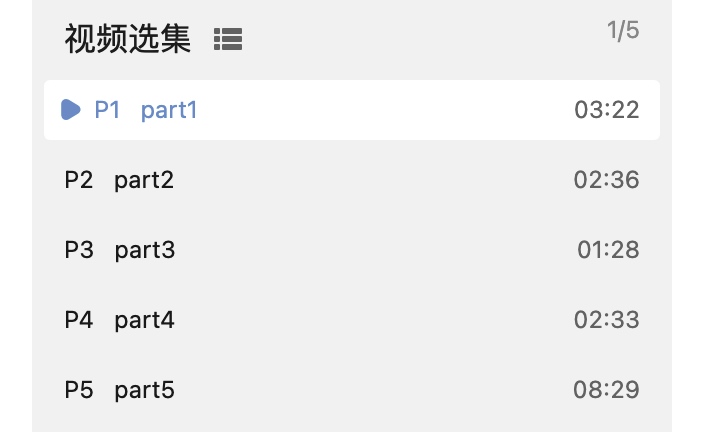

其中,URL 由 B 站主站域名 + video + 节目编号 + 参数 p 节目集数组成。
有些节目没有选集,则不需要参数 P,构造获取网页信息的时候不添加该参数即可。
解析网页,找到下载视频的链接
打开开发者工具,查找页面元素window.__playinfo__,找到在head标签的第4个 script 标签里面存有视频播放信息,baseUrl 即为视频资源链接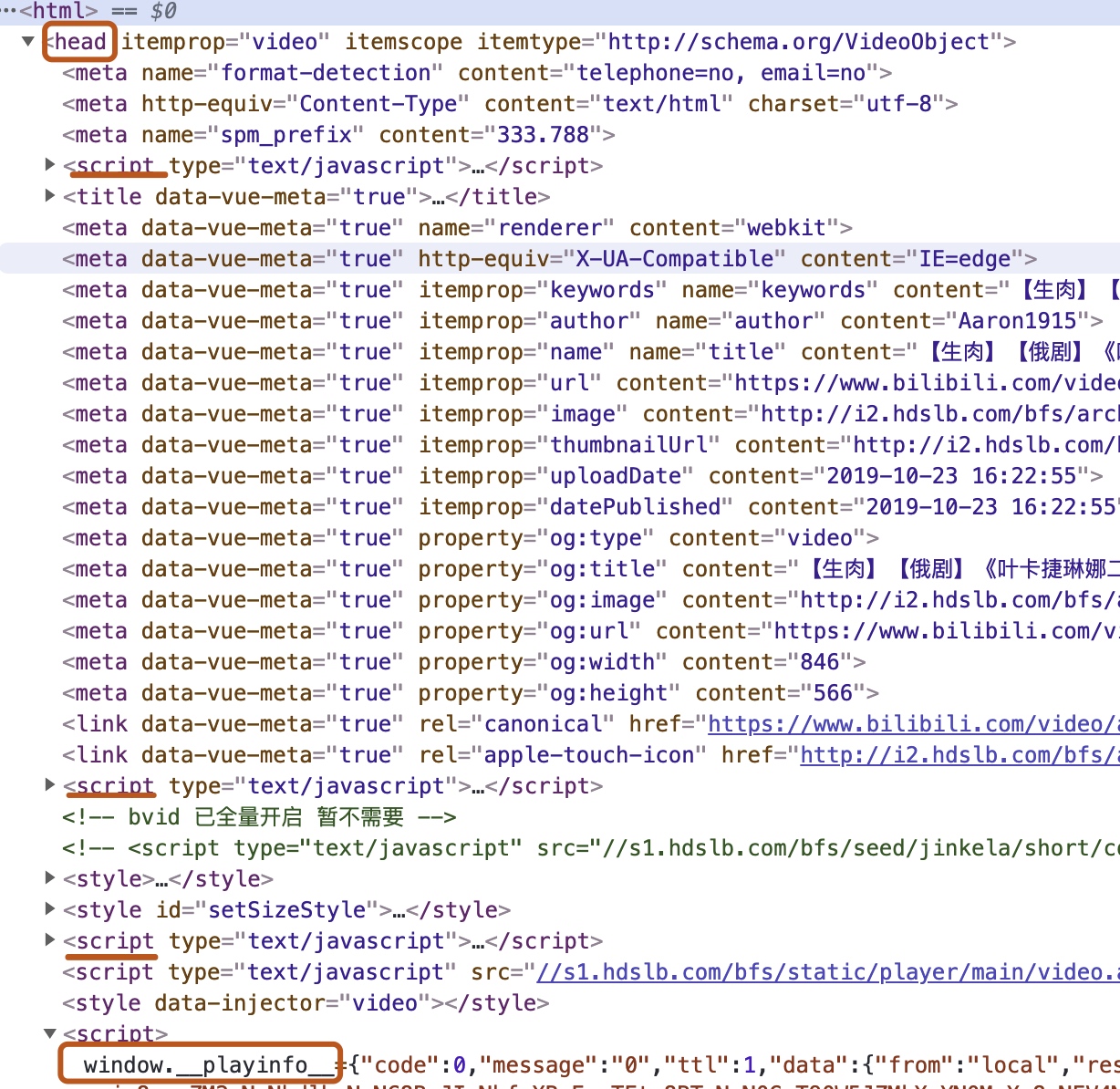

下载视频与音频
去查看视频资源的网络请求,发现一共有两种请求方式,一种是 GET,另一种是 OPTION。视频资源可能需要先发送 OPTION 请求,获取服务器许可后再请求资源,许可的保持时间较长,所以只发一次 OPTION 请求就可以了。

这里有两种下载视频的方式:
第一种是利用416报错码分片下载,Referer用于写明来源,Range用于规定分片的字节大小以及范围,每下载一定字节的资源,就修改Range,直到最后一次字节数大于剩下的资源时,服务器返回416报错,再重新将Range设置为’Range’: ‘bytes=上一次开始的索引-’。把最后剩下的资源下载下来。每获得一个视频的分片就给他拼接到文件最后,最后得到完整文件。这里使用的是第二种方法,得到了音频和视频两个文件。
第二种是不加入Range参数,直接下载整个的音频与视频,只需要注释掉添加请求头Range参数的语句即可。
合并视频与音频
对于 Bilibili 2018年以后的视频需要再多一步音频与视频合并的操作,这里通过 ffmpeg 来实现这个功能。安装 ffmpeg 参考45。
完整代码
以下代码在参考文献1的基础上进行略微修改,修改部分:combineVideoAudio 函数的命令行输出和 getBiliBiliVideo 函数中 Xpath 定位部分。另外原文是在 Windows 系统下进行的实验,本文在 MAC OS下,因此部分文件路径描述相关问题也有修改。
1 | |
例子:https://www.bilibili.com/video/BV1nE411y76r?p=1
参考资料
- 如何使用Python爬取bilibili视频(详细教程)https://zhuanlan.zhihu.com/p/148988473
- 页面元素定位 XPath 简介 https://www.cnblogs.com/feeland/p/4829093.html
- Python - 调用终端执行命令 https://www.aiuai.cn/aifarm949.html
- FFmpeg的安装和测试 https://www.jianshu.com/p/0b1c98a28fd4
- 用ffmpeg合并音频和视频 https://www.zhihu.com/question/300182407
以下是不太重要的资料:
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!