图网络基础——P3-Motifs and Graphlets
子图
我们分析网络的基本单位是节点和边,很多时候,多个相连节点构成的”小图“也具有研究价值,这样的”小图“可以称为子图(Subgraph),下图列出了一系列不同构的三节点有向子图。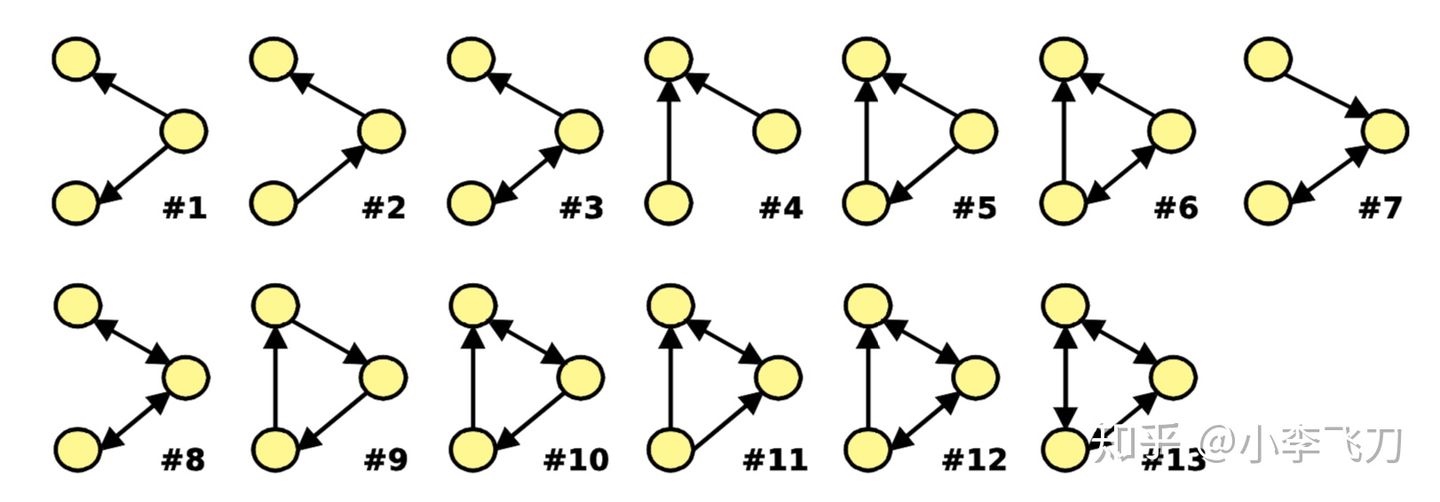
网络基序(Network Motifs)
在子图的基础上衍生出了网络基序(Network Motifs)的概念,所谓网络基序,可以理解为频繁出现的子图模式。这里有两个关键词,一个是模式,一个是频繁。
模式是指这个子图是有特定含义的,这含义可以是拓扑意义或业务意义,比如单向环形(Feed-forward loop)、双路环形(Parallel loop)、单点发散型(Single-input)。

频繁指的是这个子图在网络中的出现次数过多,怎么定义”过多“呢?我们可以把当前网络与随机网络做对比,用 $z-score$ 的方式来定义子图出现次数的异常程度。公式中的 $Z_i$ 表示第 $i$ 个 motif 的 $z-score$ 值, $N_{i}^{real}$ 表示第 $i$ 个 motif 在当前网络中的出现次数, $N_{i}^{rand}$ 表示第 $i$ 个 motif 在随机子图中的出现次数。
基序的重要性 (Significance) 意味着它比预期的要频繁。这里的关键思想是,我们说在实际网络中出现的子图比在随机网络中发生的频率要高得多。Significance 可以使用 Z-score 分数定义为:
其中 $N_{i}^{real}$ 是在真实网络 $G^{real}$ 中类型为 $i$ 的子图的数量 ,其中$N_{i}^{rand}$ 是在随机网络 $G^{rand}$ 中类型为 $i$ 的子图的数量。
公式中需要计算 $N_{i}^{rand}$,而且要计算它的均值和标准差,这就需要我们生成一系列随机图,因此需要一个生成随机图的方法。ER Graph 和Kronecker Graph可以解决这个问题,但是这里我们只关心网络的拓扑结构,最短路径和集群系数可以统统不管,只关心度分布就可以,因此可以采用一个更简单的办法,生成与当前网络的度分布完全相同的随机图。
网络的SP(significance profile) 定义为:
其中SP是归一化的 Z-scores 的向量。
配置模型(configuration model)
生成随机图的方法称为配置模型(configuration model),做法是把每个节点的度转换为对应数量的虚拟节点,然后把所有虚拟节点两两随机配对连接,再把每个节点的所有虚拟节点合并成一个节点,所有重叠的虚拟连边合并成一条边。按照上述方法生成若干张随机图,计算出每个随机图的 $N_{i}^{rand}$,然后就可以计算均值和标准差了。
配置模型 (configuration model) 是具有给定度数序列的随机图 $k_1$, $k_2$, …, $k_N$ ,可以用作“空”模型,然后与真实网络进行比较。配置模型可以很容易地生成,如图所示: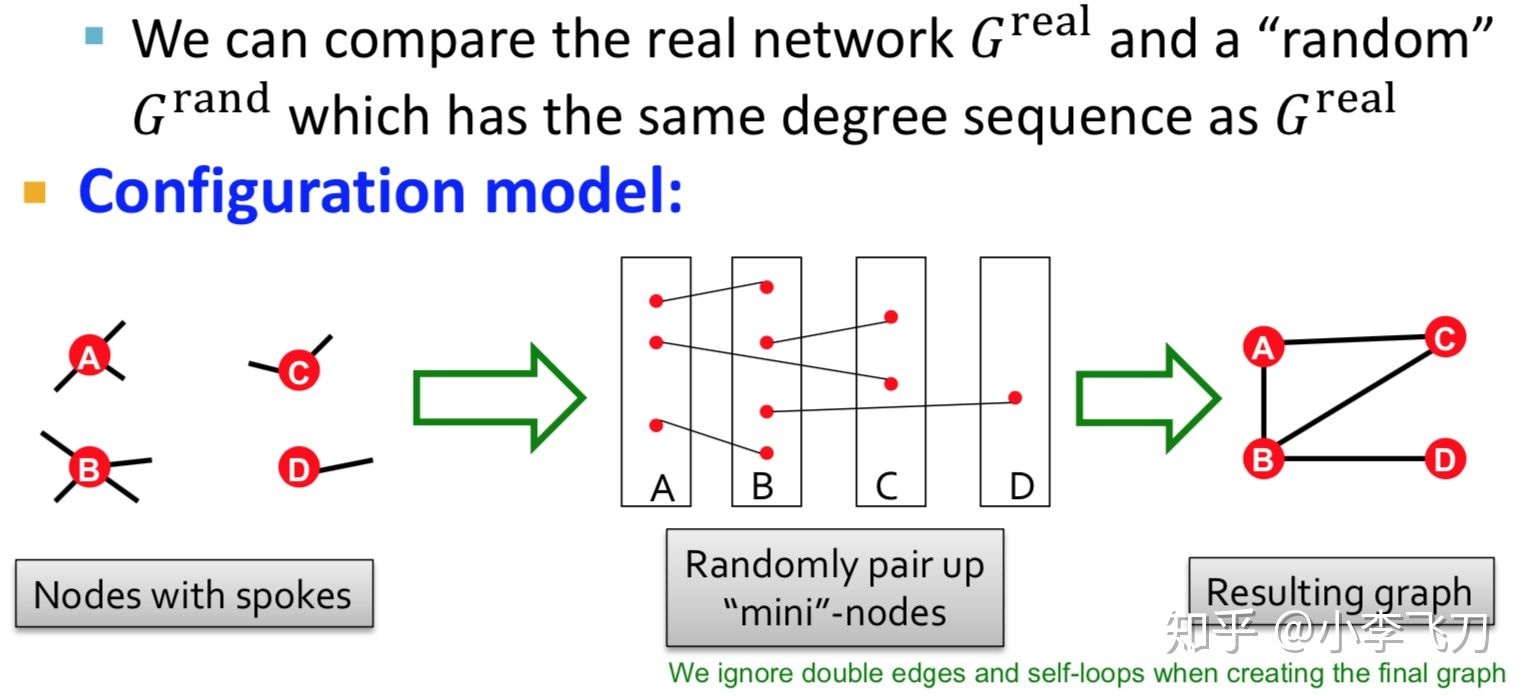
另一种生成方式如下:
- 从一个给定的图 $G$ 开始;
- 随机选择一对边 A->B, C->D , 交换端点得到 A->D, C->B, 重复以上步骤 $Q\times \vert E\vert$ 次.
通过这种方式,我们将获得一个具有相同节点度和随机重新连接边的随机重连接图。
小图(Graphlets)
小图 (Graphlets) 是连接的非同构子图。它使我们能够获得节点级子图度量。
我们想借助子图的概念,从节点入手(node-level),找到一种分析方法,这就引出了graphlets、orbit和graphlet degree vector的概念。
Graphlets指的是不同构(non-isomorphic)的子图,使我们能够获得节点级子图度量。然后我们给每一个 Graphlet 的每个节点指定轨迹角色(Orbit Position),结构对称的多个节点会视为同一种角色,比如下图中,两节点的Graphlet,两个节点属于同一种角色a,三个节点的 Graphlet,分别对应 b、c、d 三种角色的节点,更多节点的子图可以依次类推,2-5 个节点的所有子图可以划分出 73 种不同的角色。
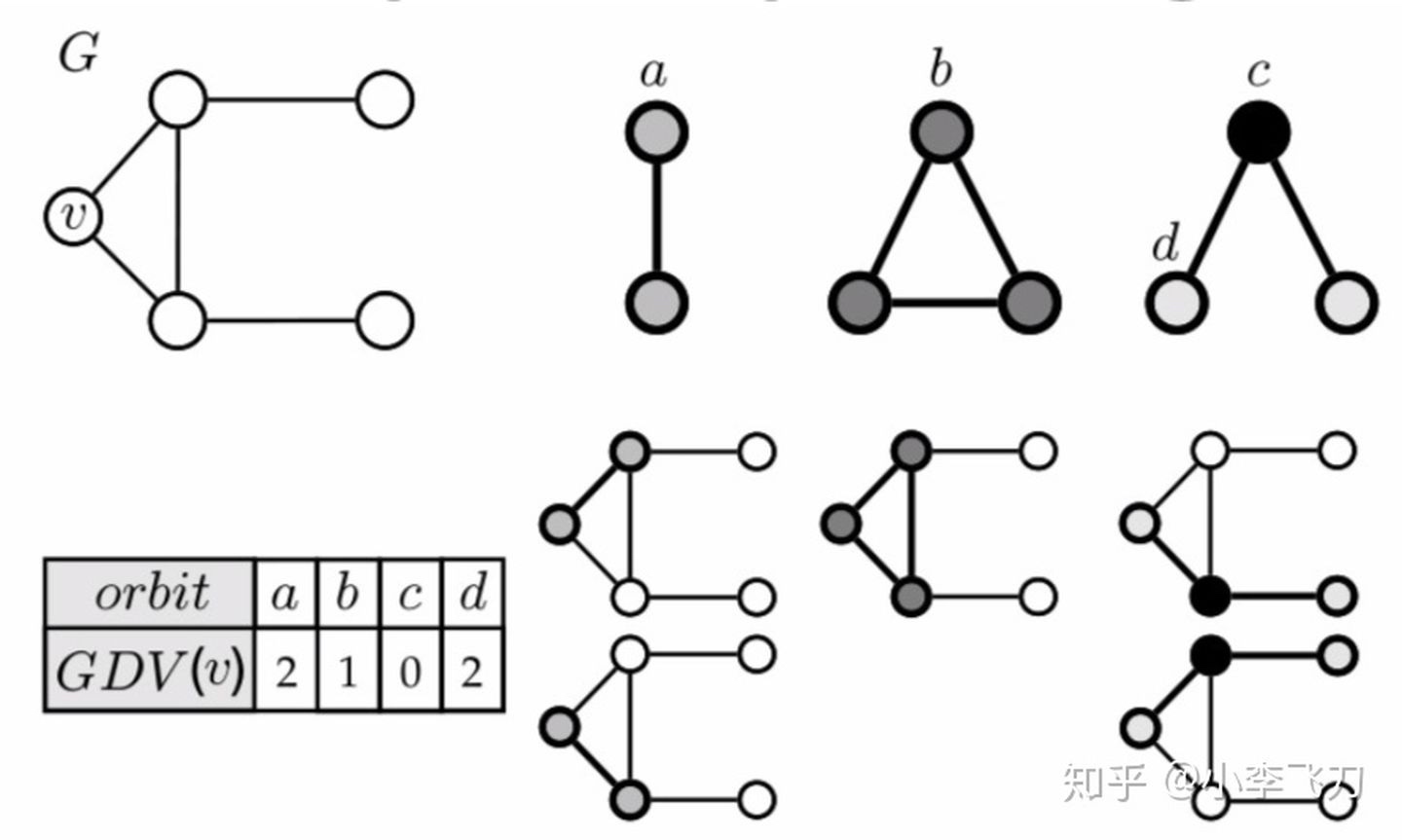
然后我们逐个分析每个节点,找出所有包含它的 Graphlet,并对它所属的角色进行计数,得到它属于每种角色的次数,下图中的节点 $v$ 包含在两个双节点 Graphlet 中,它的角色都是 a,所以 a 的计数为2,依次类推,可以得到节点 $v$ 扮演每一种角色的次数,这些计数构成的向量称为GDV(Graph Degree Vector)。
Graphlet 度向量(Graphlet Degree Vector, GDV)是在每个轨道位置具有节点的频率向量,它计算节点接触的 Graphlet 的数量。GDV提供了节点的本地网络拓扑的度量。
这里 Graphlet 的数量是人为指定的,如果你想分析2-5个节点的所有 Graphlets,就可以给每个节点生成一个长度为 73 的 GDV。GDV 的构成方法与词袋模型(Bag Of Words)有些相似,可以类比理解。
寻找网络基序和小图
仅知道图中是否存在某个子图是一个艰巨的计算问题。而且,计算时间随着 Motifs 或 Graphlet 的大小增加而呈指数增长。
Motifs和Graphlets都是以非同构子图为基础的,找到大小为 $k$ 的 Motifs 或 Graphlet ,可以分两步:
- 列举所有大小为 $k$ 的相连子图
2.计算每种子图类型的出现次数
第一步:寻找所有子图。这里的”所有“是有限可数的,比如5个节点的子图。课程里给出了一种寻找子图的方法:ESU(Exact Subgraph Enumeration),这是一个递归算法,递归迭代的两个变量是两个节点集合 $V_{subgraph}$ 和 $V_{extention}$ ,$V_{subgraph}$ 是已经划入子图的节点集合,$V_{extention}$ 是与 $V_{subgraph}$ 有连边但不属于$V_{subgraph}$ 的节点集合,算法的伪代码如下图,笔者在 networkx 和 snap 的库中都没找到该算法。
第二步:计数每一种结构的子图。首先要判断每一个子图属于哪种结构,这就涉及图同构算法,即判断两个图的结构是否完全相同。如果采用穷举法,我们需要穷举所有可能的节点映射关系,假如存在一个映射关系,使得任意两点的连接关系都相同,则说明两个图同构,否则不同构。然而,两个长度为N的序列的映射关系有 $N!$ 个,穷举的时间复杂度太高。
在图论中,判断两图是否同构是一个典型的 NP-complete 问题,常用的算法有 VF2、nauty,但是这些算法也不能保证时间开销降低到多项式级别,最好情况是 $O(N^2)$ ,最差情况仍可能是 $O(N!)$,还有一种思路是先做反向判断,即判断二者不同构,然后对可能同构的情况做进一步判断,算法细节参见networkx文档。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!